最近在弄爬虫,为了加快速度榨干硬件用上了协程,但是 cpu 使用也是特别恐怖,效果并不如预期,就在思考如何优化
思考了挺多,也用代码进行了检验
复用 Session
想法
按照 aiohttp 文档的写法 http 请求是这么发出的
1
2
3
4
5
6
7
|
async with aiohttp.ClientSession() as session:
async with session.post('https://hunsh.net/') as r:
await r.text()
|
但是在实际使用中肯定不止发送一个请求,千百万个 url 同时发送也不现实,更何况很多时候是消费者生产者模式,url 是需要从队列获取的。
我的实现方法就是在异步方法里面while not queue.empty()获得 url 发送请求,然后开大量协程调用这个异步方法。
这样子就出现了两种请求发送方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
async def worker1():
for i in range(10):
async with aiohttp.ClientSession(timeout=aiohttp.ClientTimeout(total=5), connector=aiohttp.TCPConnector(ssl=False)) as session:
async with session.post('https://hunsh.net') as r:
await r.text()
async def worker2():
async with aiohttp.ClientSession(timeout=aiohttp.ClientTimeout(total=5)) as session:
for i in range(10):
async with session.post('https://hunsh.net') as r:
await r.text()
|
然后可以编写代码进行两种实现的测试,为了避免网络情况的干扰,我的请求对象是本地服务器,内容由 nginx 直接返回,基本排除干扰
测试结果
事实上也符合我的预期了
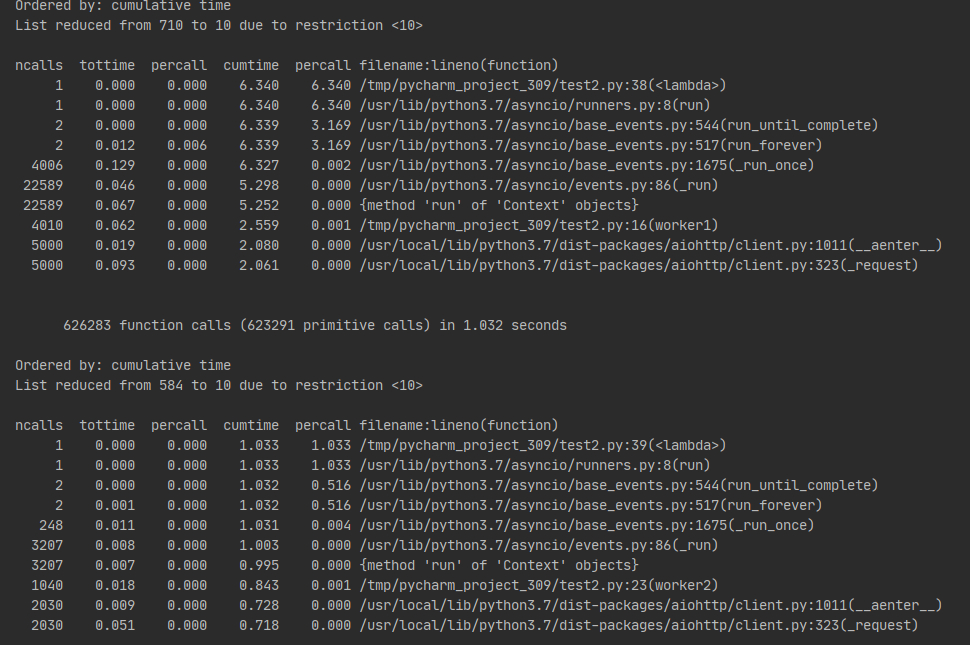
上面是 worker1,下面是 worker2,差别很明显,复用 session 的效率几乎是即用即销毁的 7 倍。
所以,复用 session 很重要!
协程数和 url 数量的选择
想法
这个想法是在做前一个测试的时候想出来的
假定 url 数量固定,且每次请求时间必然一致,每个协程的url量 * 协程量 = url总量,同时 cpu 吃满,这样 total time 理论上应该是不是只与 url 数量有关(每一个 url 需要占用 cpu 多久)呢?如果改变协程数,会不会影响用时呢?
测试结果
[这里是图]
2333 忘了截图了
在测试量小的情况下,协程数多时间有了一定的增加,但是在 url 总量大了之后,时间基本趋近一致。
结果可以得出,想法应该是没问题,只是在 url 数量较小的情况,可能会有创建协程的开销?
减少在 https 层面的消耗
想法
之前发现 cpu 消耗很大的时候有在 v2ex 发帖,有一位老哥点到 tls 也是消耗资源的。
所以诞生了两个思路:
如果目标提供 http 和 https 两个协议,尽量使用 http
如果目标仅提供 https,那么不校验证书
测试结果
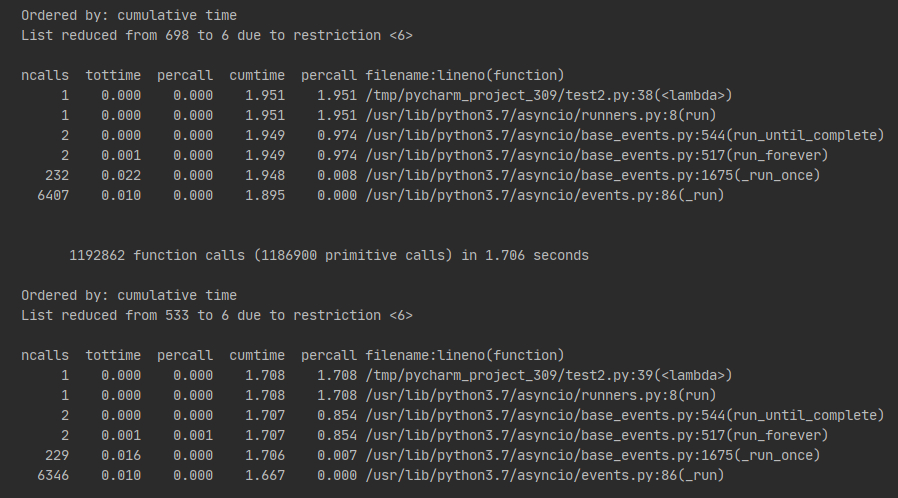
上面是 https,下面是 http,均使用 20 协程,每个协程 100 个 url
差距还是比较明显存在的,想法一证实。
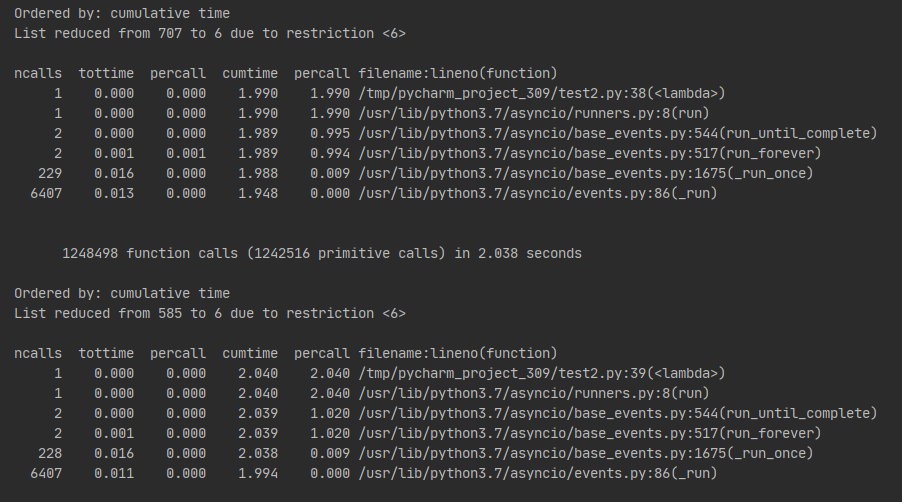
上面不校验证书,下面校验,均使用 20 协程,每个协程 100 个 url
多次试验不校验证书均有比较好的表现,想法二证实。
总结
为了节省 cpu,有以下途径
复用 Session(也没必要全局用一个,别频繁创建 session 就行了,测了,懒得贴了)
url 总量小无需特别大数量的协程
忽略证书校验(可能带来安全问题)
测试代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
import asyncio
import cProfile
import pstats
import aiohttp
def do_cprofile(func):
profile = cProfile.Profile()
profile.enable()
func()
profile.disable()
pstats.Stats(profile).sort_stats('cumtime').print_stats(6, 1.0, '.*')
async def worker1():
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False)) as session:
for i in range(100):
async with session.post('https://example.com/') as r:
await r.text()
async def worker2():
async with aiohttp.ClientSession() as session:
for i in range(100):
async with session.post('https://example.com/') as r:
await r.text()
async def main1():
await asyncio.wait([worker1() for _ in range(20)])
async def main2():
await asyncio.wait([worker2() for _ in range(20)])
do_cprofile(lambda: asyncio.run(main1()))
do_cprofile(lambda: asyncio.run(main2()))
|
其他测试代码不贴了,很简单,有兴趣自己写 1 分钟就出来了