从MongoDB迁移到PostgreSQL
原因
之前写的一个项目,由于数据都是 json,就直接使用了 MongoDB 进行数据存储,但是由于读写较为频繁,MongoDB 较低的性能就不符合需求了,遂有了迁移的念头。
迁移的是一个扁平结构的 collection,选择 PostgreSQL 是因为有 jsonb 的支持,部分字段我还是有 json 需求的。
前期准备
将需要的字段都整理出来,然后在 PostgreSQL 里建好库。
实施过程
使用 mongodbexport 导出数据为 csv
1 | |
在 PostgreSQL 命令行导入 csv
1 | |
这里要注意一个坑,尽量不要使用图形化管理软件,navicat 我显示不出创建好的表,datagrip 有个从文件导入的功能,理论上应该是可以使用,但是不知道为什么不识别 jsonb,说转换失败,但实际上在命令行可以轻松导入。
这里还会对数据进行检查,比如应该是 bigint,但是表结构只有 int,会报错。
到这数据导入就结束了,非常轻松,300 万条数据也很快。
代码修改
python 代码改了我一天时间。。。golang 还没改。。。这就只说 python 了
首先自然是 driver 库的选择,最正统的库自然是 psycopg2,要 orm 的话 SQLAlchemy 也是可以。但是我需要一个异步的库,就看到了 asyncpg
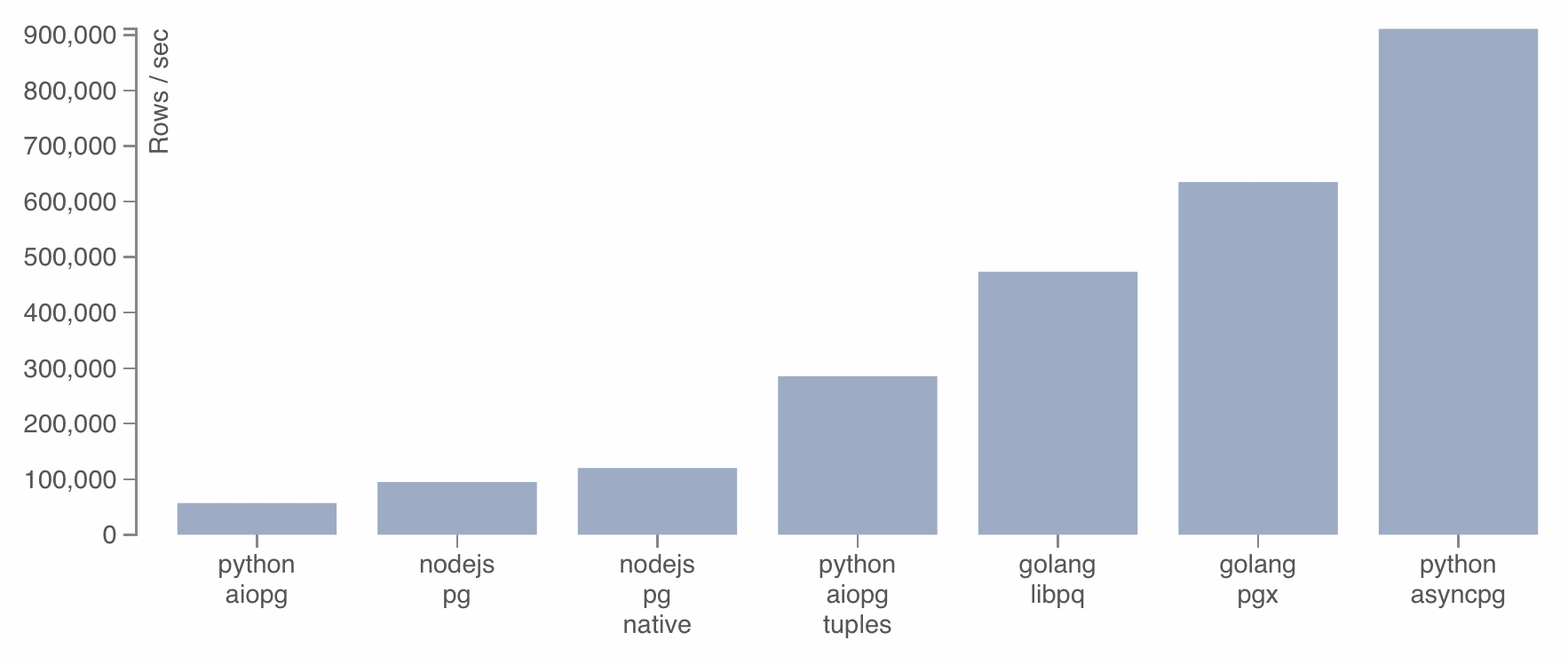
这张图还是蛮有吸引力的
不过这就只能手写 sql 了
其实查询都好说,真正的难点出现在如何实现 MongoDB 里的 Upsert 功能,也就是 PostgreSQL 如何实现 insert or update,实际上这个关键词在 google 能搜索到一大堆,官方文档也有说明,就是利用 ON CONFLICT。
但是!有如下还需解决:
如何实现像 MongoDB 这样轻松的 upsert 任意数量字段
如何最高性能批量提交
如何获取 inserted count and modified count
解决问题
—写到这突然懒了
任意字段
编写函数,for 循环很方便
高性能批量提交
可以参考stackoverflow
asyncpg 提供了 executemany,但是目测是跟 psycopg2 的一个样,只是多条语句多次提交,性能堪忧,所以需要自行优化,将多条语句合并成一条。values (record1....),(record2....),(record3....)
并且的话为了要输入数据,就是构建安全的语句,我们不能像conn.execute(sql, value1, value2)这样子做,于是找了找半天终于找到 psycopg2 的 cursor.mogrify 可以构建语句而不执行。不过因为是 cursor 游标类的函数,需要初始化,也就是需要一个连接(实际上用不到),怎么避免,其实可以自己 hack 一下,也挺有意思的。
inserted count and modified count
可以参考stackoverflow
然后结合以上几点配合大量循环就可以编写一个通用的函数完成 upsert 语句的构建
这是我写的一个没那么通用的函数,部分写死了,有一些内容没贴出来,所以直接 copy 没法用,但是如果有编程能力的应该都能够看得懂自己修改了,欢迎留言
1 | |
批量 update 的问题
可以参考stackoverflow
批量 update 会面临一个问题就是因为需要构建这么一个 SQL
1 | |
其实如果前面的问题都自己解决,那么这个问题本来也不应该有。但是这下问题出现 jsonb 上。
如果按照之前的方式来进行语句构建报错
1 | |
其实如果是UPDATE TABLE SET xxx='[1,2]' WHERE 1,是没有问题的。
但是如果在 values 里将 jsonb 数据用’[1,2]’方式,就会报错。
这个问题困扰了好一段时间,终于找到是要添加::jsonb 标识,方案已经包含在上方代码了。
写在后面
事实上迁移过程踩坑主要也有第一次使用 PostgreSQL 的原因,但是这么一弄,算是对 PostgreSQL 有了比较多的了解。
而且迁移带来的效益也是很高的。MongoDB 实在不适合在高读写频次的场景使用。